1. UNICODE란?
유니코드(Unicode)는 16비트의 단일한 값으로 전세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 산업 표준이다. 유니코드 협회(Unicode Consortium)가 제정하며, 최신판은 2008년 4월에 공개된 유니코드 5.1이다. 이 표준에는 ISO 10646 문자 집합, 문자 인코딩, 문자 정보 데이터베이스, 문자들을 다루기 위한 알고리즘 등을 포함하고 있다.
유니코드의 목적은 현존하는 문자 인코딩 방법들을 모두 유니코드로 교체하려는 것이다. 기존의 인코딩들은 그 규모나 범위 면에서 한정되어 있고, 다국어 환경에서는 서로 호환되지 않는 문제점이 있었다. 유니코드가 다양한 문자 집합들을 통합하는 데 성공하면서 유니코드는 컴퓨터 소프트웨어의 국제화와 지역화에 널리 사용되게 되었으며, 비교적 최근의 기술인 XML, 자바, 그리고 최신 운영 체제 등에서도 지원하고 있다.
유니코드에서 한국어 발음을 나타날 때는 예일 로마자 표기법의 변형인 ISO/TR 11941을 사용하고 있다.

2. UNICODE로 인코딩하기
cmd->charmap(문자표)를 연다
적당한 글자체에서 원하는 글자를 찾는다.
ex) '븀'글자를 인코딩해보자
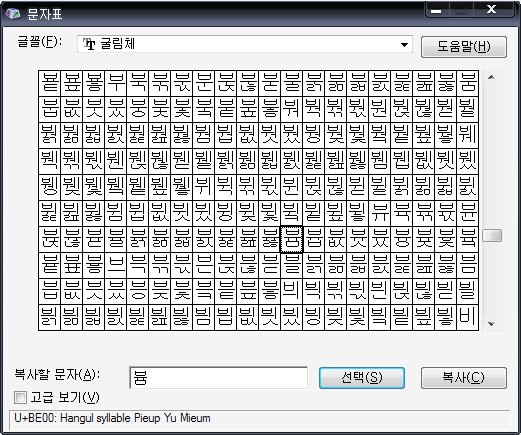
여기서 BE00는 Hex값이므로
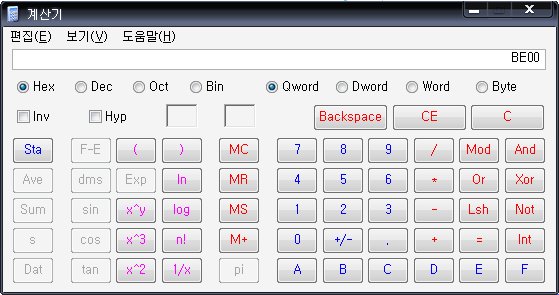
calc에서 Dex로 고쳐준다음
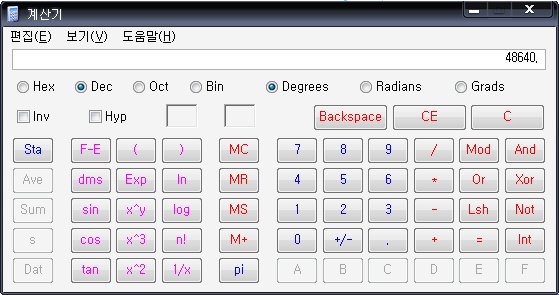
맨앞에 &#만 붙여부면 된다!
즉, '븀'을 UNICODE로 암호화하면 븀 이 된다.
참고) http://kor.pe.kr/convert.htm (유니코드변환기)
3. 부호화형식
가. UTF-8
UTF-8은 유니코드를 위한 가변 길이 문자 인코딩 방식 중 하나로, 켄 톰프슨과 롭 파이크가 만들었다. 본래는 FSS-UTF(File System Safe UCS/Unicode Transformation Format)라는 이름으로 제안되었다. UTF-8 인코딩은 유니코드 한 문자를 나타내기 위해 1바이트에서 4바이트까지를 사용한다. 예를 들어서, U+0000부터 U+007F 범위에 있는 ASCII 문자들은 UTF-8에서 1바이트만으로 표시된다. 4바이트로 표현되는 문자는 모두 기본 다국어 평면(BMP) 바깥의 유니코드 문자이며, 거의 사용되지 않는다.
나. UTF-16
다. 퓨니코드
<출처 - wikipedia http://ko.wikipedia.org/wiki/UNICODE + 내 생각>
'Information Security > Encoding' 카테고리의 다른 글
| Base64 (0) | 2009.03.17 |
|---|---|
| URL Encoding (0) | 2009.03.17 |

